Hello,
I found that interesting article while reading:
Interoperability Between Oracle and Microsoft Technologies, Using RESTful Web Servicesby John Charles (Juan Carlos) Olamendy Turruellas ACEA guide to developing REST Web services using the Jersey framework and Oracle JDeveloper 11gPublished December 2009RESTful Web services are the latest revolution in the development of Web applications and distributed programming for integrating a great number of enterprise applications running on different platforms.
Representational state transfer (REST) is the architectural principle for defining and addressing Web resources without using the heavy SOAP stack of protocols (WS-* stack). From the REST perspective, every Web application is a service; thus it's very easy to develop Web services with basic Web technologies such as HTTP, the URI naming standard, and XML and JSON parsers. (The story of RESTful Web services begins with Chapter 5 of Roy Fielding's Ph.D. dissertation, Architectural Styles and the Design of Network-Based Software Architecture, although Fielding, one of the authors of the HTTP spec, presents REST not as a reference architecture but as an approach to judging distributed architectures.)
The key to RESTful Web services is that application state and functionality are abstracted as resources on the server side. These resources are uniquely referenced by global identifiers via URI naming, and they share a uniform interface for communication with the client, consisting of a set of well-defined operations and content types. The traditional HTTP methods—POST, GET, PUT, and DELETE (also known as verbs in REST terminology)—encompass every create, read, update, and delete (CRUD) operation that can be performed on a piece of data. The GET method is used to perform a read operation that returns the contents of the resource. The POST method is used to create a resource on the server and assign a reference to this resource. The PUT method updates the resources when the client submits content to the server. And finally, the DELETE method is used to delete a resource from the server.
URI naming must be meaningful and well structured, so the clients can go directly to any state of the application through resource URIs without passing by intermediate layers. It's recommended to use path variables to separate the elements of the path in a hierarchical way. For example, to get a list of customers, the URI can be http://server/customers, and to get the customer whose identifier is 1234, the URI can be http://server/customers/1234. You must use punctuation characters to separate multiple pieces of data at the same level in the hierarchy. For example, to get customers whose identifiers are 1234 and 5678, the URI can be http://server/customers/1234;5678, with a semicolon separating the identifiers. The last tip is to use query variables to name parameters—URI naming is for designating resources, not operations, so it's not appropriate to put operation names in the URI. For example, if you want to delete the customer 1234, you should avoid the URI http://server/deletecustomers/1234; the solution is to overload the HTTP methods (POST, PUT, and DELETE).
The data exchanged across resources can be represented with MIME types such as XML or JSON documents as well as images, plain texts, or other content formats. This is specified via the Content-Type header in the requests. The format used in the application will depend on your requirements. If you want to convey structured data, the format might be XML, YAML, JSON, or CSV. If you want to transfer documents, you might use a format such as HTML, DocBook, SGML, ODF, PDF, or PostScript. You can also deal with different content for manipulating photos (JPG, PNG, BMP), calendar information (iCal), and categorized links (OPML).
And finally, RESTful Web services need protocols to transfer states that must be client/server, stateless, cacheable, and layered, so there can be any number of connectors (client, servers, caches, tunnels, firewalls, gateways, routers) that transparently mediate the request.
There are two types of states in RESTful Web services: resource and application. The resource state is information about resources, stays on the server side, and is sent to the client only in the form of representation. The application state is information about the path the client has taken through the application, and it stays on the client side until it can be used to create, modify, and delete resources.
A RESTful Web service is by nature stateless, and if the client wants the states to take part of the request, then it must be submitted as part of the underlying request. Statelessness is a very important feature for supporting scalability in your solution, because no information is stored on the server (this is responsibilities of the client) and none of it is implied from previous requests. If you have a workload balancer and a request cannot be handled by one server, another one can process this request, because message requests are self-contained, and we don't need to refactor the solution architecture.
Ruby on Rails is an open source Web development framework for the Ruby programming language. You can create a Web application very easily to expose relational data, using REST principles. Django, another open source Web development framework, was written for the Python programming language, following the model-view-controller (MVC) design pattern.
And finally, for Java developers, JAX-RS (JSR 311) provides an API for creating RESTful Web services according to REST principles. JAX-RS uses annotations (Java 5 and above) to simplify the development effort for Web services artifacts, so you can expose simple Plain Old Java Objects (POJOs) as Web resources. There are several JAX-RS-based implementations, such as Jersey, JBoss RESTEasy, Restlet, Apache CXF, and Triaxrs. This article explains how to develop REST Web services by using the Jersey framework (the Sun reference implementation for JAX-RS) and Oracle JDeveloper 11g. (At the time of this writing, Oracle is planning to support JAX-RS in the near future by using the Jersey framework approach, integrated with Oracle JDeveloper tools and Oracle WebLogic Server.)
To set up the environment to develop the RESTful Web service with the Jersey framework, download the Jersey libraries with all the necessary dependencies from https://jersey.dev.java.net/. After you reach this site, you can see that Jersey contains several major parts:
- Core server. A set of annotations and APIs (standardized in JSR-311) to develop a RESTful Web service
- Core client. The client API for communicating with REST services
- Integration. A set of libraries for integrating Jersey with Spring, Guice, Apache Abdera, and so on
For our demonstration REST solution, we need only the following three Java Archive (JAR) files from the Jersey download: jersey.jar, asm-3.1.jar, and jsr311-api.jar.
Developing the RESTful Web Service with Oracle TechnologiesThis article's example application features a common business scenario in which a client needs to search for detailed information about business entities by using a Web service and the client applications and server applications are running on different platforms. The RESTful Web service is developed with Oracle JDeveloper 11g and the Jersey framework running on the Oracle platform, and the front-end application is a console application, developed with Microsoft Visual Studio .NET 2008 and Microsoft .NET Framework 3.5, that consumes the Web service and displays the underlying client data. We're going to use RESTful Web service technologies as the key integration layer between the client and the server.
Let's start with the server-side application. Open the Oracle JDeveloper 11g IDE, and create a new application by entering the application name and the directory for storing the files in the dialog box.
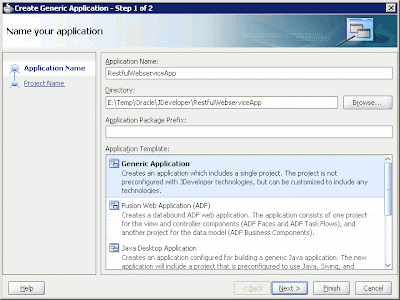
Figure 1: Creating a new application
The next step is to add a Web project to the application by choosing File -> New. When the New Gallery dialog box appears, select the Projects node from the Categories pane and select the Web Project item.
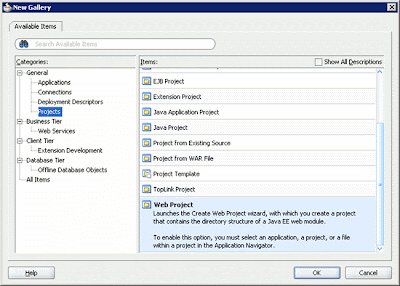
Figure 2: Creating a Web project
The Create Web Project wizard appears. Click Next. On the Location page, enter the project name and the directory of the project within the application's working directory. Then click Next.
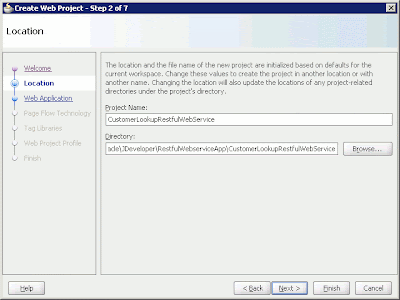
Figure 3: The Create Web Project wizard's Location page
On the Web Application page, select Servlet 2.5\JSP 2.1 (Java EE 1.5) to set up the Web technology to be used by the application. Click Next. On the Page Flow Technology page, select None and click Next. On the Tag Libraries page, click Next to go to the next page without choosing any tag library. The last page of the wizard is the Web Project Profile page, where you enter the document root, Web application name, and context name. Click Finish.
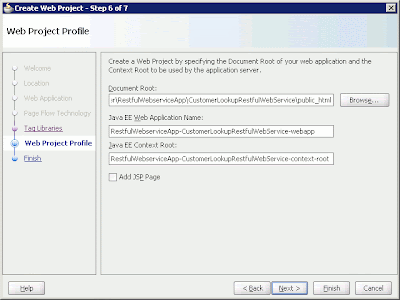
Figure 4: The Create Web Project wizard's Web Project Profile page
Now we need to include the Jersey framework in the libraries of Oracle JDeveloper 11g by selecting Tool -> Manage Libraries, launching the Manage Libraries dialog box, and clicking New to open the Create Library dialog box. The next step is to enter a meaningful name for this managed library, such as Jersey Framework, and then click Add Entry and browse to the directory where the Jersey libraries are deployed. For this example, we need to include the asm-3.1.jar, jersey.jar, and jsr-311.jar JARs. Remember to check the Deployed by Default check box.
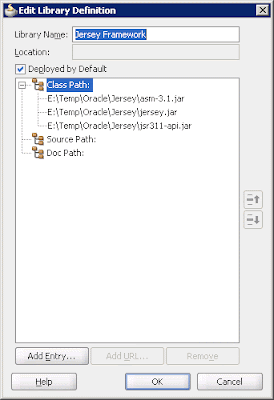
Figure 5: Adding JARs for the Jersey framework
After clicking OK, return to the Manage Library dialog box. The setting is shown below.
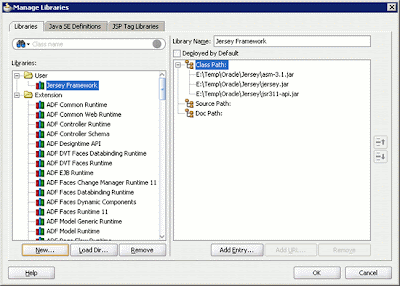
Figure 6: The Jersey framework is added to the Oracle JDeveloper 11g managed libraries.
The next step is to right-click the Web project and select Properties. Go to the Libraries and Classpath node, click Add Library, and select the Jersey Framework library. The Libraries and Classpath setting is shown below.
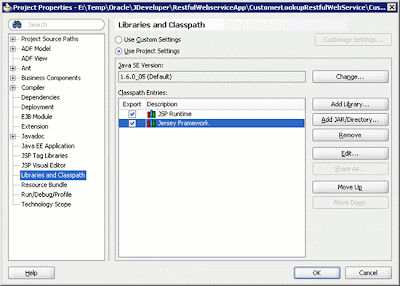
Figure 7: Libraries and Classpath settings
Now, according to the programming model for RESTful Web services, we need to define an application whose state and functionality are abstracted into resources. Every resource is uniquely addressable with URIs. All resources share a uniform interface for transferring state and functionality from resources and clients by using basic HTTP operations and by sending the object data, using any established content format (string, XML, JSON, and so on). Each resource invokes the business services to process the request and then create the underlying response.
In the JAX-RS standard, a resource class is a POJO class annotated with an @Path annotation to represent a particular REST resource and at least a method annotated with @Path or a request method designator such as @GET, @PUT, @POST, or @DELETE to handle requests and specific operations such as creating, reading, updating, and deleting resources.
The first step is to define the business entity whose state will be persisted in the payload of the RESTful message. In our case, we want to send information concerning our customers, so let's create a Customer class in the domainobjects package (see below).
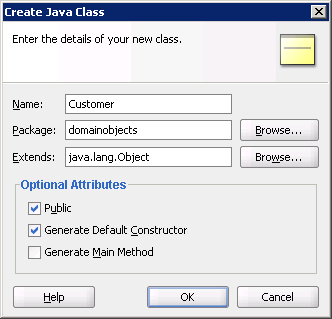
Figure 8: Creation of the Customer class in the domainobjects package
Next, let's define the attributes as well as the setter and getter properties for the customer entity type, such as the identifier, full name, and age fields. In real-world situations, we must characterize a customer entity with a lot of fields. We also have to override the toString method in order to return an XML representation of a customer. Our definition of the Customer class is shown below.
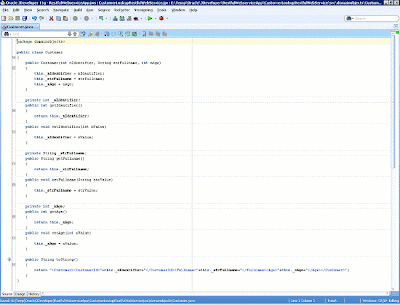
Figure 9: Creation of the Customer class in the domainobjects package
We also need to define an entity manager for the customers. The entity manager is responsible for the main data operations, acting as a gateway to the database on behalf of the customer entity. In order to focus on the development of the RESTful Web service and not on the creation of data access objects, this article avoids any interaction with database systems and defines a Java array of customers to simulate the underlying querying operation. Then the entity manager will return a list of available customers by using the getCustomers method and enable getting a particular customer, given that customer's identifier, with the getCustomerById method.
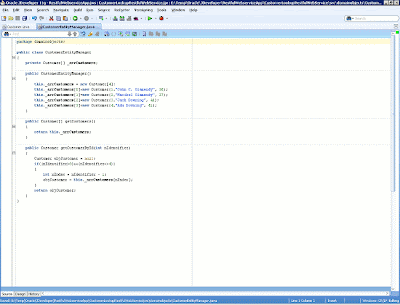
Figure 10: Definition of the CustomerEntityManager class
For a real-world scenario requiring interaction with relational datasources, it's recommended to use built-in features of Oracle JDeveloper 11g and Oracle Application Development Framework (Oracle ADF) technologies (data control and data bindings) for developing a robust persistent layer.
The next step is to specify that all REST requests should be redirected to the Jersey container. This involves defining a servlet dispatcher in the application's web.xml file. In this case, the ServletRestfulWS servlet will map to the pattern /resources/*, and the base URL for accessing the REST resources is http://{remote_server}:{remote_port}/{app_context}/resources/. We also include the index.jsp page as the welcome page for the applications' entry point, although it's not necessary. Besides declaring the Jersey servlet, we also need to define an initialization parameter indicating the Java packages that contain the resources. In this case, the restfulresources package where our resources, developed in Java, reside (see below).
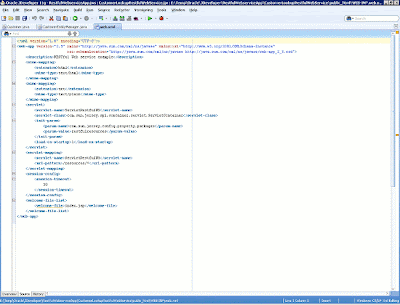
Figure 11: Configuring the Jersey dispatcher in the web.xml file
The next step is to define a resource named CustomerResource for accepting HTTP GET requests and sending back information about the customers. Let's create the CustomerResource class in the restfulresources package (see below).
Figure 12: Creation of the CustomerResource class in the restfulresources package
The CustomerResource class is the root resource class for our application. Root resources classes are POJO classes that are either annotated with an @Path annotation or have at least one method annotated with an @Path annotation or a request method designator such as @GET, @PUT, @POST, or @DELETE. In this case, we're going to get information about customer entities. The code for the CustomerResource class is shown below.
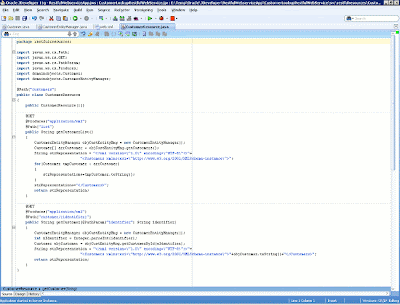
Figure 13: Definition of the CustomerResource class
The business logic for the CustomerResource class, being exposed with REST Web services, is to get a list of customers (by invoking the getCustomerList method) and detailed information about a particular customer (by invoking the getCustomer method and passing its identifier as a parameter).
Now I'll explain the annotations used in this example. First, all the annotations are defined in javax.ws.rs.*, part of the JAX-RS (JSR 311) specification. Because in the REST world, resources are key citizens, we need a way to access them. The @Path annotation identifies the URI path template to which resources respond. The URI path template is relative to the base URI of the server and port (in this case, localhost and 7101), the context root of the Web application (in this case, RestfulWebserviceApp-CustomerLookupRestfulWebService-context-root), and the URI pattern to which the Jersey servlet responds (in this case, resources as defined in web.xml). This approach concerning the URI path template in REST is very useful for building dynamically URIs for our REST application. In our application, the root resource is annotated with the @Path("customers") annotation, so this is the entry point to operations involving the customer entities of our application. Because a resource can have subresources (a way to access attributes and methods of the underlying resource class), we can define a subresource for accessing the getCustomerList method by using the @Path("list") annotation and accessing the method by using the http://{remote_server}:{remote_port}/{app_context}/resources/customers/list URI.
hint: For more about
Microsoft .net outsourcing, Oracle outsourcing and
Oracle outsourcing company at the
software outsourcing company: www.symbyo.com
We can also define a subresource for accessing the getCustomer method by using the @Path("customer/{identifier}") annotation and access the customer whose identifier is 1 by using the http://{remote_server}:{remote_port}/{app_context}/resources/customers/customer/1 URI. In this case, the URI path template includes variables, which are denoted with curly braces and substituted for by the Jersey framework at runtime. To obtain the values of these variables and match them with the underlying request method, we need to use the @PathParam("identifier") annotation in the definition of the method parameter.
The @GET annotation in both methods is a request method designator—along with@POST, @PUT, @DELETE, and @HEAD—that is defined by JAX-RS and corresponds to the similarly named HTTP methods. It means that the methods process only HTTP GET requests.
The @Produces annotation specifies which MIME types are supported for responses. In this case, it's application/xml, although it could be any content format such as an image, JSON, HTML, or plain text.
To successfully deploy and run the RESTful application in the embedded Oracle WebLogic Server, we need to do some tricky work here, because Oracle JDeveloper 11g does not know how to deploy Jersey applications to Oracle WebLogic Server. We need to create a weblogic.xml file along with web.xml in the WEB-INF directory of the Web application (see below).
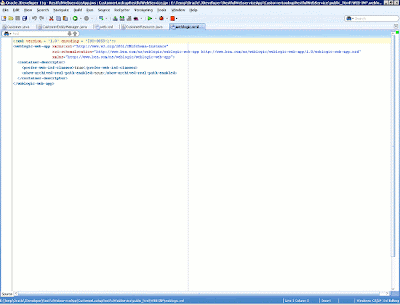
Figure 14: Oracle WebLogic Server deployment file
Finally, we're going to use another trick by adding an empty index.jsp page to the project. After that, right-click this JSP page and select the Run option from the context menu. When the application server is launched and the application is deployed there, you can see the results.
When you browse to the RESTful application with Internet Explorer, you get the results shiwn below.

Figure 15: List of customers returned from the RESTful Web service
The screenshot below displays the detailed information for the customer, with its identifier, 1.
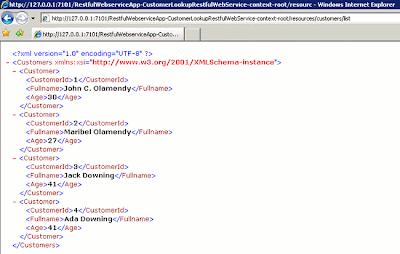
Figure 16: The customer with identifier 1 returned by the RESTful Web service
Consuming the RESTful Web Services with Microsoft .NET TechnologiesTo create the client-side part of the solution, let's open Visual Studio .NET 2008, select File -> New -> Project, and navigate in the Project Types tree to the Windows node on the Visual C# subtree. Select Console Application from Templates, and then enter descriptive names for the project, solution, and directory where you'll store the underlying files (see below).
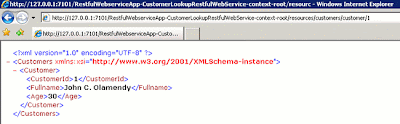
Figure 17: Creation of a new Console Application project
In Microsoft .NET 3.5 and Windows Communication Foundation (WCF) 3.5, there are two methods for consuming a RESTful Web service. The first one is by using the new WebHttpBinding, which is used to configure endpoints that are exposed through HTTP requests instead of SOAP messages. So we can simply invoke a service by using a URI, sending an HTTP request, and deserializing the response to an object model. WCF supports different message formats such as XML, JSON, and raw binary data. Another way to consume RESTful services is to manually create an HTTP request including all the parameters as part of the URI, get the response, and parse the data on the response payload.
In the sample application for this article, I will use the second strategy to consume the RESTful Web service. The System.Net.HttpWebRequest implements the logic for processing the request and the response to a Web server. For the creation of the Web request, we need to use the factory method to create an instance of the request HttpWebRequest class based on the passed URI as the parameter. In this case, the URI instance is dynamically generated by the arguments passed to the application. If there are no arguments and we want a list of customers, we will use the http://127.0.0.1:7101/RestfulWebserviceApp-CustomerLookupRestfulWebService-context-root/resources/customers/list address. Otherwise, the address will be based on the argument representing the customer identifier, such as http://127.0.0.1:7101/RestfulWebserviceApp-CustomerLookupRestfulWebService-context-root/resources/customers/customer/1 for the customer with identifier 1.
After that, the request is sent when we invoke the GetResponse methodby returning an instance of the System.Net.HttpWebResponse class. Because the HttpWebResponse class implements the System.IDisposable interface to release external resources, the GetResponse method is called in a using block to enable the Dispose method to be called when the WebResponse instance is no longer needed, permitting the network connection to be closed.
If the Web request to the server results in an HTTP error code (4xx or 5xx), a WebException instance will be thrown. Otherwise, the GetResponseStream method on the HttpWebResponse instance will be called, returning a System.IO.Stream instance that can be read from to process the payload of the response.
In this case, the message payload contains an XML document representing the list of customers. To process the XML document directly, we need to load the stream (representing the XML payload) into an XPathDocument.
There are two options for parsing the XML document. The first strategy is to deserialize the XML document to an object model representing the business entities. This is the more elegant solution, because it establishes a clear separation between the persistent medium and the business logic. The other way is to parse the XML document directly and display the result as it appears in the parsing process. The inconvenience of this strategy is that there is a semantic mismatch, because we don't know the meaning of the data and its structure. In this example, we're just displaying the payload of the response message and not taking into consideration any semantic issues, so we're going to follow the second strategy, so we don't lose focus on the RESTful solution (see the code snippet below).
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.IO;
using System.Net;
using System.Xml.XPath;
namespace RestfulWSClientConsoleApp
{
class Program
{
static void Main(string[] args)
{
Uri uriRestfulWS = null;
if (args.Length>0)
{
string strUri = String.Format("http://127.0.0.1:7101/RestfulWebserviceApp-CustomerLookupRestfulWebService-context-root/resources/customers/customer/{0}", args[0]);
uriRestfulWS = new Uri(strUri);
}
else
{
uriRestfulWS = new Uri("http://127.0.0.1:7101/RestfulWebserviceApp-CustomerLookupRestfulWebService-context-root/resources/customers/list");
}
try
{
HttpWebRequest objWebRequest = (HttpWebRequest)WebRequest.Create(uriRestfulWS);
using (HttpWebResponse objWebResponse = (HttpWebResponse)objWebRequest.GetResponse())
{
XPathDocument objXmlDoc = new XPathDocument(objWebResponse.GetResponseStream());
XPathNavigator objXPathNav = objXmlDoc.CreateNavigator();
foreach (XPathNavigator objNode in objXPathNav.Select("/Customers/Customer"))
{
string strCustomerId = objNode.SelectSingleNode("CustomerId").ToString();
string strFullname = objNode.SelectSingleNode("Fullname").ToString();
string strAge = objNode.SelectSingleNode("Age").ToString();
System.Console.WriteLine("Customer Information. Id={0}, Fullname={1}, Age={2}", strCustomerId, strFullname, strAge);
}
}
}
catch (WebException objEx)
{
System.Console.WriteLine("Web Exception calling the RESTful Web service. Message={0}", objEx.Message);
}
}
}
}
Finally, let's run the console application, passing as an argument the customer identifier 1. The output resembles that shown below.
 Conclusion
ConclusionNow that you have read this article explaining how to create RESTful Web services by using Oracle technologies such as Oracle JDeveloper 11g, the Jersey framework (the reference implementation of the JAX-RS [JSR 311] specification), and Oracle WebLogic Server as well as how to consume the Web service by using Microsoft technologies such as Visual Studio .NET 2008 and the .NET 3.5 framework, you can adapt your own Web solutions to be extended with this revolutionary approach.
________________
Juan Carlos (John Charles) Olamendy Turruellas [johnx_olam@fastmail.fm] is a senior integration solutions architect, developer, and consultant. His primary focus is object-oriented analysis and design, database design and refactoring, enterprise application architecture and integration using design patterns, and management of software development processes. He has extensive experience in the development of enterprise applications using Microsoft and Oracle platforms as well as in distributed systems programming, business process integration, and messaging with principles of service-oriented architecture (SOA) and related technologies. He has been awarded Most Valuable Professional (MVP) status by Microsoft several times and is an Oracle ACE.
Source: http://www.oracle.com


























